Mountains of Misunderstanding: The AI Confidence Trap
The Mountains of Misunderstanding map the gap between what we think we know and what we actually know — a gap that AI widens by packaging fluency as expertise. A year after writing this article, spec-driven development became my structural answer to staying off the mesa.
AI & Machine Learning Series — 25 articles
- Using ChatGPT for C# Development
- Trivia Spark: Building a Trivia App with ChatGPT
- Creating a Key Press Counter with Chat GPT
- Using Large Language Models to Generate Structured Data
- Prompt Spark: Revolutionizing LLM System Prompt Management
- Integrating Chat Completion into Prompt Spark
- WebSpark: Transforming Web Project Mechanics
- Accelerate Azure DevOps Wiki Writing
- The Brain Behind JShow Trivia Demo
- Building My First React Site Using Vite
- Adding Weather Component: A TypeScript Learning Journey
- Interactive Chat in PromptSpark With SignalR
- Building Real-Time Chat with React and SignalR
- Workflow-Driven Chat Applications Powered by Adaptive Cards
- Creating a Law & Order Episode Generator
- The Transformative Power of MCP
- The Impact of Input Case on LLM Categorization
- The New Era of Individual Agency: How AI Tools Empower Self-Starters
- AI Observability Is No Joke
- ChatGPT Meets Jeopardy: C# Solution for Trivia Aficionados
- Mastering LLM Prompt Engineering
- English: The New Programming Language of Choice
- Measuring AI's Contribution to Code
- Building MuseumSpark - Why Context Matters More Than the Latest LLM
- Mountains of Misunderstanding: The AI Confidence Trap
Introduction
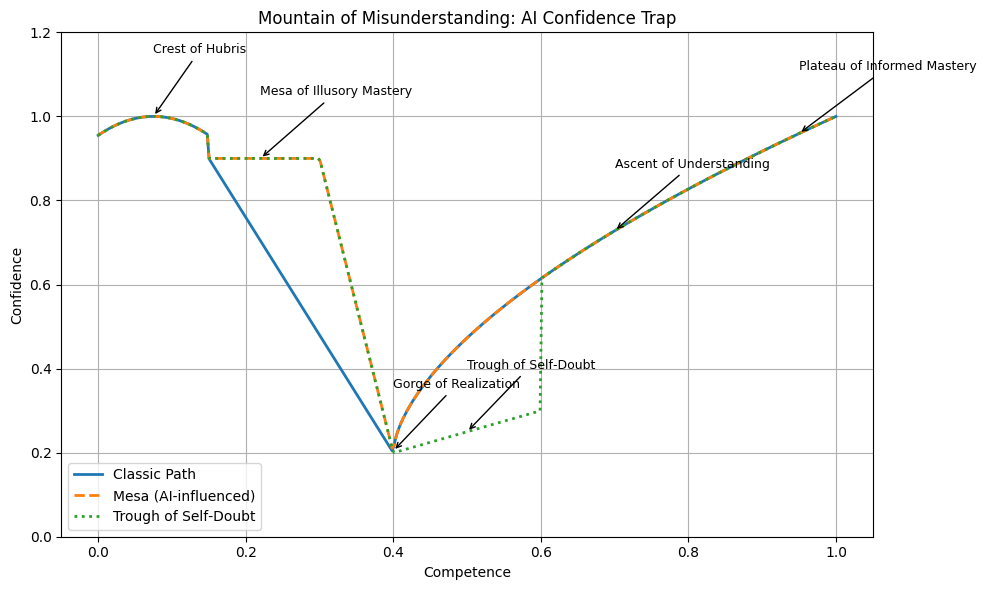 The Learning Curve: From Crest to Plateau
The Learning Curve: From Crest to Plateau
A year ago I let an AI coding agent run on a task I should have interrupted earlier. It spun up extra terminal instances for processes that were already running, then got stuck chasing a side issue with increasing confidence. For a few minutes, I trusted the fluency and ignored the friction.
That moment bothered me enough to write this article. Now, a year later, I am developing production Python applications — something I would not have claimed competence in twelve months ago. What changed was not the tools. The story of how I got there taught me something about the trap I had just described.
AI is excellent at producing convincing output, and that changes how we evaluate our own competence. The risk is not that AI is bad for learning. The risk is that confidence and competence can drift apart while everything still sounds polished. I explored the judgment side of this pattern in AI and Critical Thinking in Software Development, and the same tension keeps showing up in day-to-day engineering decisions.
I call this pattern the Mountains of Misunderstanding. It maps the gap between what you think you know and what you actually know — the terrain that appears when confidence and competence move at different speeds. Not a law of learning, and not a path everyone must follow. A warning system. A way to notice when confidence is climbing faster than understanding.
The landscape has a shape worth knowing before you enter the story. Early learning produces a burst of false confidence — the Crest of Hubris. With AI, that confidence can flatten into a long plateau I call the Mesa of Illusory Mastery, where the output looks professional but the understanding is shallow. And then there is the Gorge of Realization — the moment you discover how much you don't know. The chart above traces this path. What follows is the story of how I walked that terrain, and what I found on the other side.
The Mesa, the Gorge, and the Spec
In my agent example, the failure was not catastrophic — that is what made it dangerous. Nothing crashed. I just watched momentum drift while the tool sounded increasingly certain. Ask a question, get a clean response, walk away feeling smarter. But was I actually smarter? Or was I echoing certainty I hadn't earned?
In mid-2025, I was a .NET architect with decades of C# experience. Python was a language I had read about, used in scripts, but never shipped in production. When I needed to build a production Python application, my instinct was to open a chat window and start prompting. The model would have produced clean code. I would have felt productive. And I would have been on what I call the Mesa of Illusory Mastery — the flat plateau where the application runs, the tests pass, the code looks reasonable, but there is no specification, no architectural reasoning on record, no articulation of trade-offs. You do not know what you built. You know what you prompted.
The model produces clean syntax without modeling temporal behavior, concurrency constraints, or system boundaries — the things that make production code different from demo code. I recognized the trap because I had just written about it. So instead of prompting my way to a running application, I tried something different. I started writing a constitution for the project — the architectural principles, the patterns to follow, the patterns to avoid. Then a specification for each feature. Then a plan. Then a task list. Only then did the AI agent start generating code.
The first spec I wrote for a Python service included a line about retry logic with exponential backoff. Clean, professional, borrowed from patterns I knew in C#. When the agent generated the implementation, I stared at it and realized I could not tell whether it was right. I had specified something I understood conceptually but not in Python's idiom — not the async model, not the library conventions, not the failure modes. That was the Gorge of Realization. Not dramatic. Just honest. I had to stop and learn what I had claimed to already know.
That is where the confidence trap breaks. You cannot specify what you do not understand. Every gap in your knowledge surfaces as a gap in the specification, and you either close it or acknowledge it before the first line of production code exists.
What followed was months of what I can only call the Trough of Self-Doubt. Writing specs felt slow. The model could generate code faster than I could specify it. The temptation to skip the spec and just prompt was constant. But the specs kept catching decisions I would have missed — assumptions about concurrency, packaging conventions I had never questioned, error handling patterns that C# muscle memory got wrong in Python.
Slowly, the real climb began. Not fluent yet, but able to evaluate what the model produced against what the specification demanded. The spec became the external check that prompt-driven development never provided. Confidence started to align with competence — not because I felt confident, but because I had the receipts. The specification documented what I intended. The implementation matched it. When someone asked why, I could point to architectural reasoning, not a chat transcript.
This is not willpower. This is structure. Willpower-based solutions — "I'll be more careful," "I'll double-check the output," "I'll test more thoroughly" — are what I was recommending a year ago, and they failed. Not because the intentions were bad, but because nothing enforced them. A specification enforces them by design. You cannot skip the thinking when the thinking is the deliverable. The idea is older than AI — CASE tools, S-Designer, and PowerBuilder all tried versions of it decades ago. The tools changed. The core insight did not: understand first, then build.
Where the Distortion Gets Dangerous
Two transitions matter more than the labels.
The first is the slide onto the Mesa — where AI keeps you comfortable for too long. You get immediate answers, clean explanations, and very little resistance. Progress feels fast, but the underlying model in your head never gets stress-tested. One clean prompt response and the gap between intention and competence disappears from view. AI can make sprint charts look great while silently increasing architectural debt — and the mesa feels even more comfortable when velocity metrics confirm it.
The second is the drop into the Gorge, followed by months of self-doubt. In practice, this is where teams overcorrect. People either stop trusting themselves entirely or stop using the tool responsibly. Both reactions are expensive.
In my own workflow, this is when I ask a hard question: if the model disappeared right now, could I still explain the decision path and defend it? If the answer is no, I am not on a summit. I am on a mesa. And if there is no specification, there is no decision path to explain. As I wrote in Measuring AI's Contribution to Code, the question was never "how much code did AI write?" — it was always "who understood the decisions behind the code?"
The Real Challenge: Structure Over Willpower
The Mountains of Misunderstanding are not a destiny. They are what appears when confidence and competence move out of sync. A year ago, my answer was self-awareness — notice when you are on a mesa, test yourself, correct course. That advice was not wrong. It was not enough.
What I have learned since is that the gap needs structural reinforcement, not just introspection. The spec is that structure. It is the proof that understanding happened before generation began.
The Goal: Structure Over Willpower
The real challenge is not avoiding AI. It is building workflows that force your confidence and competence to stay aligned — so you do not have to rely on catching yourself on the mesa after you are already there.
Explore More
- Why I Built DevSpark -- How spec-driven development evolved into a practical governance framework
- From Oracle CASE to Spec-Driven AI Development -- A 40-year journey through model-driven engineering
- Measuring AI's Contribution to Code -- The question was never how much code AI wrote
- AI and Critical Thinking in Software Development -- The judgment side of the confidence-competence gap
- Dogfooding DevSpark -- What happens when you use a prompt tool to refine a prompt tool


