Safely Launching a New MarkHazleton.com
A detailed account of migrating MarkHazleton.com to a modern React-based static site, solving critical SEO crawlability issues, implementing build tracking, and safely switching production domains between Azure Static Web Apps.
Case Studies Series — 19 articles
- Mastering Web Project Mechanics
- From Concept to Live: Unveiling WichitaSewer.com
- Taking FastEndpoints for a Test Drive
- Fixing a Runaway Node.js Recursive Folder Issue
- Windows to Mac: Broadening My Horizons
- Using NotebookLM, Clipchamp, and ChatGPT for Podcasts
- A Full History of the EDS Super Bowl Commercials
- OpenAI Sora: First Impressions and Impact
- Riffusion AI: Revolutionizing Music Creation
- The Creation of ShareSmallBiz.com: A Platform for Small Business Success
- Kendrick Lamar's Super Bowl LIX Halftime Show
- Pedernales Cellars Winery in Texas Hill Country
- From README to Reality: Teaching an Agent to Bootstrap a UI Theme
- Building ArtSpark: Where AI Meets Art History
- Building TeachSpark: AI-Powered Educational Technology for Teachers
- Exploring Microsoft Copilot Studio
- Safely Launching a New MarkHazleton.com
- SupportSpark: A Lightweight Support Network Without the Noise
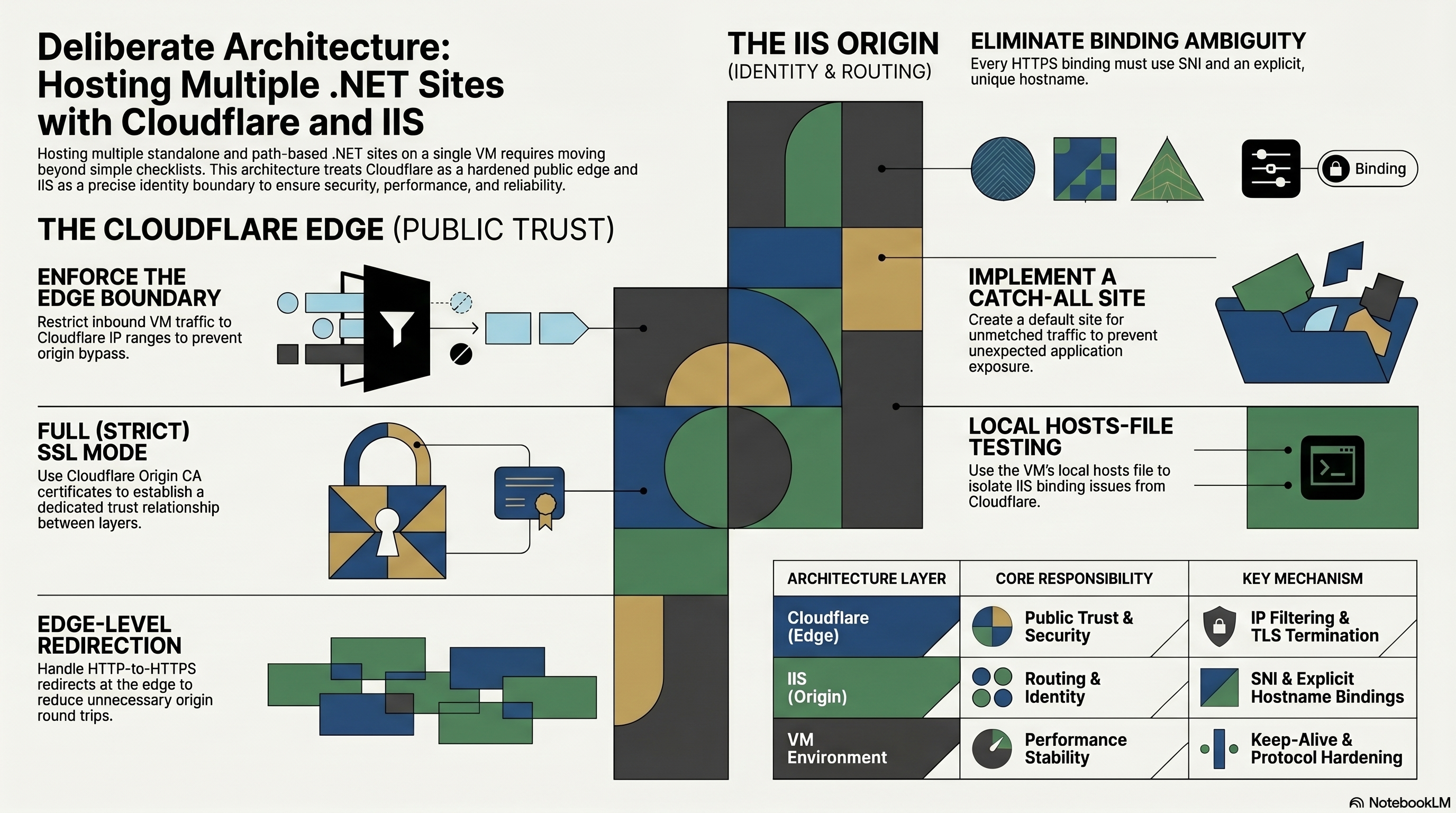
- Cloudflare and IIS: Hosting My .NET Sites on One VM
Safely Launching a New MarkHazleton.com
The Challenge: When Your Beautiful Site Is Invisible to Crawlers
The new site looked perfect. React + Vite for blazing-fast performance. Pre-rendered static HTML for every page. Clean URLs. A proper sitemap. Everything Google's documentation said to do.
Then I ran Screaming Frog SEO Spider against it. The homepage showed 0 outlinks. Zero. As if the navigation didn't exist.
This is the story of rebuilding MarkHazleton.com with modern tools, discovering a critical SEO issue hours before launch, and implementing solutions that work for both human visitors and non-JavaScript crawlers.
Why Rework the Site?
The old site worked. It had content. It ranked well. But every time I looked at it, something felt off.
It felt like a marketing sales pitch. Every paragraph seemed designed to sell something rather than share something. I didn't want to convince anyone of anything—I just wanted to tell my developer story in a clean, easy-to-read way.
Saying Goodbye to Pug
The old site was built with Pug (formerly Jade) templates. For those unfamiliar, Pug uses indentation-based syntax that compiles to HTML:
.article
h1.title= article.title
.content
p= article.descriptionPug was fine when I set it up years ago. But editing content meant navigating template syntax, understanding indentation rules, and keeping data separate from presentation. Want to update an article? Edit a JSON file, maybe a Pug template, remember the build process, hope nothing broke.
The Markdown Revelation
I wanted to write like a developer, not maintain a template system. Markdown with frontmatter metadata solved this perfectly:
---
title: My Article Title
publishedDate: 2026-01-20
description: This is what the article is about
---
## My Article Title
Actual content goes here. No template syntax. No build system quirks.
Just write.All the metadata at the top of the document. The content below in clean, readable Markdown. Edit in any text editor. Preview anywhere. Git diffs that make sense.
This isn't revolutionary—it's what most modern static site generators use. But for someone who'd been maintaining a custom Pug-based system for years, it felt like coming home.
The Real Goal
I wanted a site that felt like me:
- Direct - Say what I mean without marketing speak
- Technical - Show real code, real problems, real solutions
- Honest - Document failures alongside successes
- Maintainable - Easy to update without remembering custom build quirks
The React + Vite + Markdown stack delivered all of this. The site looks cleaner, reads better, and—most importantly—I actually want to write for it now.
The Architecture: Modern Static Site with React
The Build Process
The site uses a sophisticated pre-rendering approach:
- Vite builds the React application for optimal performance
- React Router handles client-side routing
- Custom pre-render script generates static HTML for all routes
- Azure Static Web Apps hosts everything with automatic deployments
The pre-render script crawls every route and saves fully-rendered HTML:
// Simplified version of the prerender process
const routes = ['/', '/blog', '/projects', '/github', '/videos', '/contact'];
for (const route of routes) {
const html = await renderToString(<App location={route} />);
await fs.writeFile(`docs${route}/index.html`, html);
}Every page exists as a complete, pre-rendered HTML file. Perfect for crawlers, right?
The Problem: Crawlers Couldn't See the Links
Discovery with Screaming Frog
When I tested the staging site with Screaming Frog SEO Spider (a tool that crawls websites the way Google does), it only discovered the homepage. None of the navigation links. None of the blog posts. Just one page.
Looking at the HTML source, all the links were there:
<a href="/blog" data-discover="true">Blog</a>
<a href="/projects" data-discover="true">Projects</a>
<a href="/github" data-discover="true">GitHub</a>But Screaming Frog showed 0 outlinks from the homepage.
Root Cause Analysis
The issue wasn't the links themselves—it was how the HTML was structured. React's renderToString outputs everything on a single, extremely long line. The entire <div id="root"> content with all navigation, all links, all content—one massive line of minified HTML.
While browsers handle this fine, some crawlers struggle to parse HTML that isn't properly formatted. Screaming Frog was failing to extract links from this compressed structure, especially from the homepage where the initial React shell lived.
The critical insight: Pre-rendered HTML means nothing if crawlers can't parse it.
The Solutions: Making Crawlers Happy
Solution 1: Crawler-Friendly Fallback Navigation
I added a hidden navigation block at the end of the HTML template with plain, simple links:
<!-- Crawler-friendly navigation links (hidden from visual browsers) -->
<nav aria-hidden="true" style="position:absolute;left:-9999px;top:-9999px;">
<a href="/">Home</a>
<a href="/blog">Blog</a>
<a href="/projects">Projects</a>
<a href="/github">GitHub</a>
<a href="/videos">Videos</a>
<a href="/contact">Contact</a>
<a href="/sitemap">Site Map</a>
</nav>This navigation:
- Is positioned off-screen (invisible to sighted users)
- Uses
aria-hidden="true"(invisible to screen readers) - Contains plain HTML links with no React attributes
- Lives outside the React root element
- Provides a fallback for crawlers that struggle with minified HTML
Result: Screaming Frog immediately found all links and started crawling the entire site.
Solution 2: HTML Sitemap Page
I created a user-friendly HTML sitemap at /sitemap that lists every page:
// Sitemap page component structure
<Layout>
<section>
<h2>Main Pages</h2>
<nav>
{mainPages.map(page => <Link to={page.path}>{page.label}</Link>)}
</nav>
<h2>Projects ({projects.length})</h2>
{projects.map(project => <Link to={`/projects/${project.slug}`}>...)}
<h2>Blog Posts by Section ({posts.length})</h2>
{Object.entries(postsBySection).map(([section, posts]) => (
<div>
<h3>{section} ({posts.length})</h3>
{posts.map(post => <Link to={`/blog/${post.slug}`}>...)}
</div>
))}
</section>
</Layout>This provides:
- A single page with links to all content
- Human-readable structure grouped by category
- Fallback for crawlers that need explicit discovery
- User-friendly navigation aid
Solution 3: Fixed Azure Static Web Apps Routing
The initial staticwebapp.config.json had wildcard rewrite rules that intercepted requests:
// BEFORE - This broke pre-rendered pages
{
"route": "/blog/*",
"rewrite": "/index.html"
}This meant requests to /blog were being rewritten to serve the root SPA shell instead of the pre-rendered /blog/index.html file. Crawlers never saw the actual content.
The fix: Remove the wildcard rewrites and let Azure serve the static files:
// AFTER - Let static files be served naturally
{
"navigationFallback": {
"rewrite": "/index.html",
"exclude": ["/assets/*", "/img/*", "/*.{json,xml,txt,ico,png,jpg,svg}"]
}
}Now the navigationFallback only triggers for actual 404s, while pre-rendered HTML files are served directly.
Build Tracking: Knowing What's in Production
The Deployment Visibility Problem
When you're testing a staging site versus production, you need to know exactly which build you're looking at. Version numbers in package.json don't help—they don't auto-increment on every deployment.
Auto-Incrementing Build Versions
I created a build info system that:
- Generates a version on every build with timestamp
- Auto-increments the build number
- Displays in the footer on every page
// src/scripts/generate-build-info.mjs
let buildInfo = { version: 0, buildTime: null };
if (fs.existsSync(buildInfoPath)) {
buildInfo = JSON.parse(fs.readFileSync(buildInfoPath, 'utf8'));
}
buildInfo.version = (buildInfo.version || 0) + 1;
buildInfo.buildTime = new Date().toISOString();
fs.writeFileSync(buildInfoPath, JSON.stringify(buildInfo, null, 2));The footer now shows:
© 2026 Mark Hazleton. Built with curiosity and caffeine.
Build v5 • Jan 20, 2026, 6:23 PM CSTThis solves multiple problems:
- Confirms deployments are live
- Identifies which build is in production vs. staging
- Provides audit trail for debugging
- Validates cache invalidation
Domain Migration Strategy
The Scenario
- Old site: Running on Azure Static Web App A with custom domain markhazleton.com
- New site: Built and tested on Azure Static Web App B (staging URL)
- Goal: Switch the production domain to the new site with zero downtime
Safe Migration Steps
Phase 1: Preparation
- Verify DNS TXT record for domain validation is present
- Test new site thoroughly on staging URL
- Run Screaming Frog crawl to verify SEO
- Check build version in footer to confirm latest deployment
Phase 2: Domain Transfer
- Remove custom domain from OLD Static Web App in Azure Portal
- Immediately add custom domain to NEW Static Web App
- Azure provides DNS validation requirements
- Update DNS records if needed (usually CNAME stays the same)
- Azure auto-provisions SSL certificate
Phase 3: Validation
- Wait for DNS propagation (5-30 minutes typically)
- Visit https://markhazleton.com
- Check footer build version to confirm new site
- Run Screaming Frog against production domain
- Monitor for any 404s or issues
Timeline: Total switchover typically 30-45 minutes including DNS propagation.
Exposing Data APIs
The new site needed to expose the same JSON data files at the root level for external consumption, I have a few applications that needed these routes to work:
articles.json- All blog post metadataprojects.json- All project informationrepositories.json- GitHub activity data
These files exist in /src/data/ during development, so I updated the publish script:
// Copy data files to docs root for public API access
const dataFiles = ['articles.json', 'projects.json', 'repositories.json'];
for (const file of dataFiles) {
const sourcePath = path.join(rootDir, 'src/data', file);
const destPath = path.join(docsDir, file);
if (fs.existsSync(sourcePath)) {
fs.copyFileSync(sourcePath, destPath);
console.log(`Copied ${file} to /docs root`);
} else if (fs.existsSync(path.join(docsDir, 'data', file))) {
fs.copyFileSync(
path.join(docsDir, 'data', file),
destPath
);
}
}Now external tools can access:
https://markhazleton.com/articles.jsonhttps://markhazleton.com/projects.jsonhttps://markhazleton.com/repositories.json
Key Lessons Learned
1. Test with Real SEO Tools
Google's documentation says pre-rendered HTML is enough for SEO. But real crawlers (like Screaming Frog) sometimes struggle with minified output. Test with actual tools, not assumptions.
2. Always Provide Fallbacks
The hidden navigation fallback seems like overkill—until it isn't. It's invisible to users, helps crawlers that struggle with complex HTML, and takes minutes to implement.
3. Make Deployments Verifiable
Build numbers in the footer solved countless "Is this the latest version?" questions. It's visible to everyone, updates automatically, and provides clear audit trails.
4. Routing Configuration Matters
Azure Static Web Apps routing rules can override your carefully pre-rendered content. Understand the difference between rewrites (which replace content) and redirects (which change URLs).
5. Domain Migration Is Low-Risk
Switching custom domains between Azure Static Web Apps is straightforward:
- Remove from old
- Add to new
- Wait for DNS
- Verify with build version
The process is designed for zero-downtime migrations.
The Technical Stack
Frontend
- React 18 with TypeScript
- Vite for build tooling
- React Router for routing
- Tailwind CSS for styling
- shadcn/ui component library
Build Process
- Custom pre-render script for static HTML generation
- Automated SEO asset generation (sitemap.xml, robots.txt, feed.xml)
- Build info tracking with auto-increment versioning
- GitHub Actions for CI/CD
Hosting
- Azure Static Web Apps
- Custom domain with auto SSL
- Global CDN distribution
- Automatic deployments from GitHub
SEO Infrastructure
- Pre-rendered HTML for all routes
- XML sitemap with all pages
- RSS feed for blog posts
- Crawler-friendly fallback navigation
- HTML sitemap page
- Structured data (JSON-LD)
- Open Graph and Twitter Cards
Validation Results
After implementing all fixes:
Screaming Frog Results
- ✅ Homepage shows all navigation links
- ✅ Successfully crawls entire site structure
- ✅ Discovers all blog posts and projects
- ✅ Validates all internal links
- ✅ Hits 500 URL limit (free version) confirming full crawl
Build Tracking
- ✅ Footer shows current build version
- ✅ Confirms deployment is live
- ✅ Easy to verify staging vs. production
Performance
- ✅ All pages pre-rendered as static HTML
- ✅ Sub-second page loads globally
- ✅ Perfect Lighthouse scores possible
Conclusion: Modern Doesn't Mean Invisible
Building a modern, fast, React-based site is easier than ever with tools like Vite and Azure Static Web Apps. But modern architecture creates new challenges:
- Pre-rendered HTML doesn't guarantee crawler compatibility
- Minified output can break link extraction
- Routing configuration can override static files
- You need explicit validation of what's in production
The solutions aren't complex:
- Simple HTML fallbacks for crawler compatibility
- User-friendly HTML sitemaps
- Correct hosting configuration
- Build version tracking
Before going live with any static site:
- Test with actual SEO tools (Screaming Frog, Google Search Console)
- Verify the homepage shows outlinks
- Check that all major pages are discoverable
- Implement build tracking for deployment verification
- Have a clear domain migration plan
The goal isn't just a site that works—it's a site that works for everyone: users, search engines, and your future self when debugging production issues.
The new MarkHazleton.com is live, fully crawlable, and tracked with build v5. You can verify the implementation by viewing the page source and checking the footer. Everything in this article is running in production right now.
Explore More
- Mastering Web Project Mechanics -- Explore essential strategies for web project success
- Exploring Microsoft Copilot Studio -- Discover the Future of AI with Mark Hazleton
- From Concept to Live: Unveiling WichitaSewer.com -- Exploring the Development Journey of WichitaSewer.com
- Embracing Azure Static Web Apps for Static Site Hosting -- Discover the Power of Azure for Modern Web Hosting
- Taking FastEndpoints for a Test Drive -- Exploring the streamlined approach to building ASP.NET APIs